

Trending





Catogery Tags
a.i. AEO AGI AI Arduino artificial intelligence automation BiBli BiBli OS Business Intelligence Caleb Eastman Cellular ChatGPT Cleaning Coding Music Colorado Data Deep Learning Elon Musk Google hacking Hinton How to HVOB Innovation IoT Jalali Hartman Lex Fridman Machine Learning Microsoft NVIDIA OpenAI Raspberry Pi ROBAUTO Robauto.ai Robotics Robots Sam Altman Search SEO Signals Space TESLA Trump Who Is
-

Start Building More Nuclear Plants: Why Token Training in Language Models Requires Massive Energy
In recent years, language models have transformed the way we interact with… Know More
-
-
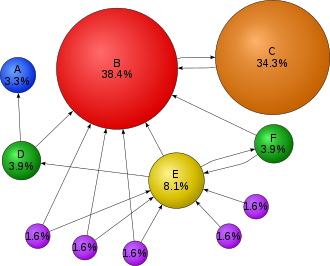
What does Machine Learning have to do with SEO
Whether you like it or not, or even want to think about… Know More
-

HoneyBadger and the Digitization Gap
Society is badly in need of automation and robotics. The issue is… Know More
-
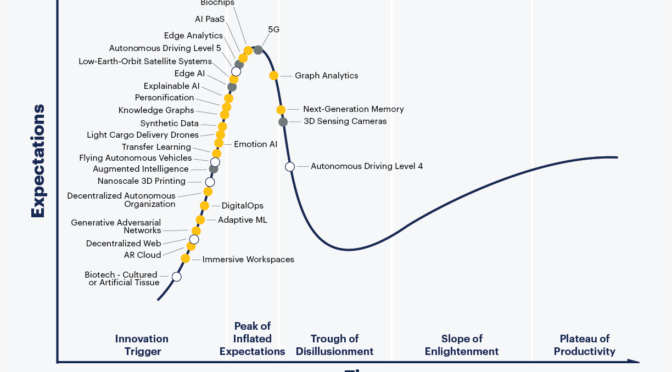
Misconceptions about Machine Learning
There is quite a bit of buzz about A.I. these days. At… Know More
-

-

Lex Fridman’s Deep Learning State of the Art 2020
Lex Fridman gave a great comprehensive 2020 look at Artificial Intelligence in… Know More
-

Deep Learning 101 with MIT’s Lex Fridman
Lex Fridman from MIT has put together some great resources around Deep… Know More
-
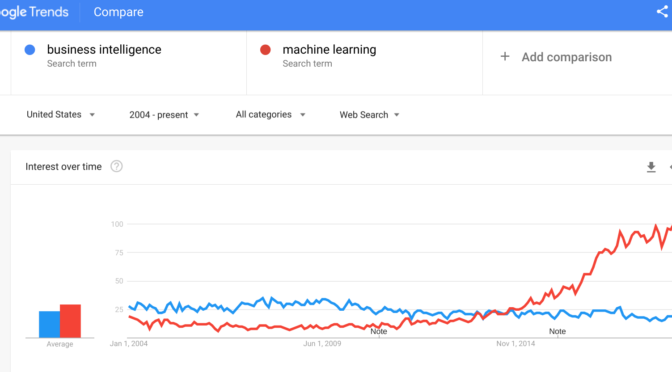
Top 2020 A.I. Trend: The Switch to Machine Learning
It’s that time of year again. When the internet gets flooded with… Know More