

Decision Trees: Understanding the Basics and How They Can Be Used in Machine Learning
Machine learning has become an integral part of many industries, from finance to healthcare to marketing. It involves the use of algorithms and statistical models to analyze data and make predictions or decisions without explicit instructions. One of the most commonly used techniques in machine learning is decision trees. In this article, we will explore the basics of decision trees and how they can be used in machine learning.
Decision trees are a type of supervised learning algorithm that is used for both classification and regression tasks. They are called decision trees because they resemble a tree-like structure, with branches representing different possible outcomes and nodes representing decision points. The goal of a decision tree is to create a model that predicts the value of a target variable by learning simple decision rules inferred from the data features.
The first step in building a decision tree is to select a root node, which is the most important feature in the dataset. This feature is used to split the data into two or more subsets. The splitting process continues until a stopping criterion is reached, such as when all the data points in a subset belong to the same class or when there are no more features to split on. The final nodes of the tree are called leaf nodes and contain the predicted outcome.
One of the main advantages of decision trees is their interpretability. Unlike other machine learning models, decision trees provide a clear and easy-to-understand visual representation of the decision-making process. This makes it easier for non-technical stakeholders to understand and trust the model’s predictions. Additionally, decision trees can handle both numerical and categorical data, making them suitable for a wide range of datasets.
There are different types of decision trees, such as ID3, C4.5, and CART. ID3 (Iterative Dichotomiser 3) is one of the earliest decision tree algorithms and uses the information gain metric to select the best feature for splitting. C4.5 is an improved version of ID3 that can handle missing values and continuous attributes. CART (Classification and Regression Trees) is a more advanced algorithm that can handle both classification and regression tasks.
Decision trees can be used for a variety of tasks, such as predicting customer churn, identifying fraudulent transactions, and diagnosing diseases. In marketing, decision trees can be used to segment customers based on their characteristics and behaviors, allowing companies to target their marketing efforts more effectively. In healthcare, decision trees can assist doctors in making diagnoses by analyzing patient data and identifying patterns that may indicate a particular disease.
One of the challenges of using decision trees is overfitting, which occurs when the model is too complex and performs well on the training data but fails to generalize to new data. To avoid overfitting, techniques such as pruning and setting a minimum number of data points for each leaf node can be used. Pruning involves removing unnecessary branches from the tree, while setting a minimum number of data points ensures that each leaf node has enough data to make accurate predictions.
In conclusion, decision trees are a powerful and versatile machine learning model that can be used for a variety of tasks. They are easy to interpret, can handle both numerical and categorical data, and can be used for both classification and regression tasks. However, they also have their limitations, such as the potential for overfitting. With proper techniques and careful consideration of the data, decision trees can be a valuable tool in the field of machine learning.
Linear Regression: A Simple Yet Powerful Model for Predictive Analytics
Machine learning has become an integral part of many industries, from finance to healthcare to marketing. It involves using algorithms and statistical models to analyze data and make predictions or decisions without explicit instructions. One of the most commonly used machine learning models is linear regression, which is a simple yet powerful tool for predictive analytics.
Linear regression is a statistical method that aims to find the relationship between two or more variables. It is a supervised learning technique, meaning that it requires a labeled dataset to train the model. The goal of linear regression is to find a line that best fits the data points, allowing us to make predictions about the relationship between the variables.
The most basic form of linear regression is simple linear regression, which involves only two variables – a dependent variable and an independent variable. The dependent variable is the one we want to predict, while the independent variable is used to make the prediction. For example, in a study on the relationship between hours spent studying and exam scores, the dependent variable would be the exam score, and the independent variable would be the number of hours spent studying.
To find the best-fitting line, linear regression uses a method called least squares. This method calculates the distance between each data point and the line, squares it, and then adds up all the squared distances. The line with the smallest sum of squared distances is considered the best fit for the data.
Once the line is determined, we can use it to make predictions about the relationship between the variables. For example, if we have a new student who studied for 5 hours, we can use the line to predict their exam score. This is the power of linear regression – it allows us to make predictions based on the data we have.
Simple linear regression is useful when there is a clear linear relationship between the variables. However, in real-world scenarios, this is often not the case. This is where multiple linear regression comes in. It is an extension of simple linear regression that allows for more than one independent variable. This is useful when there are multiple factors that can affect the dependent variable.
For example, in a study on housing prices, the dependent variable would be the price of the house, and the independent variables could be the size of the house, the number of bedrooms, and the location. By using multiple linear regression, we can take into account all these factors and make more accurate predictions about the price of a house.
Another type of linear regression is logistic regression, which is used for classification problems. Unlike simple and multiple linear regression, which predict continuous values, logistic regression predicts discrete values. It is commonly used in binary classification problems, where the dependent variable has only two possible outcomes.
For example, in a study on the likelihood of a person having a heart attack, the dependent variable would be whether or not the person had a heart attack, and the independent variables could be age, gender, and lifestyle habits. By using logistic regression, we can predict the probability of a person having a heart attack based on these factors.
In conclusion, linear regression is a simple yet powerful model for predictive analytics. It allows us to find the relationship between variables and make predictions based on that relationship. Whether it is simple linear regression, multiple linear regression, or logistic regression, this model has proven to be useful in a wide range of industries and applications. As technology continues to advance, we can expect to see even more sophisticated versions of linear regression being developed and used in various fields.
Neural Networks: Exploring the Complexities and Applications of Deep Learning
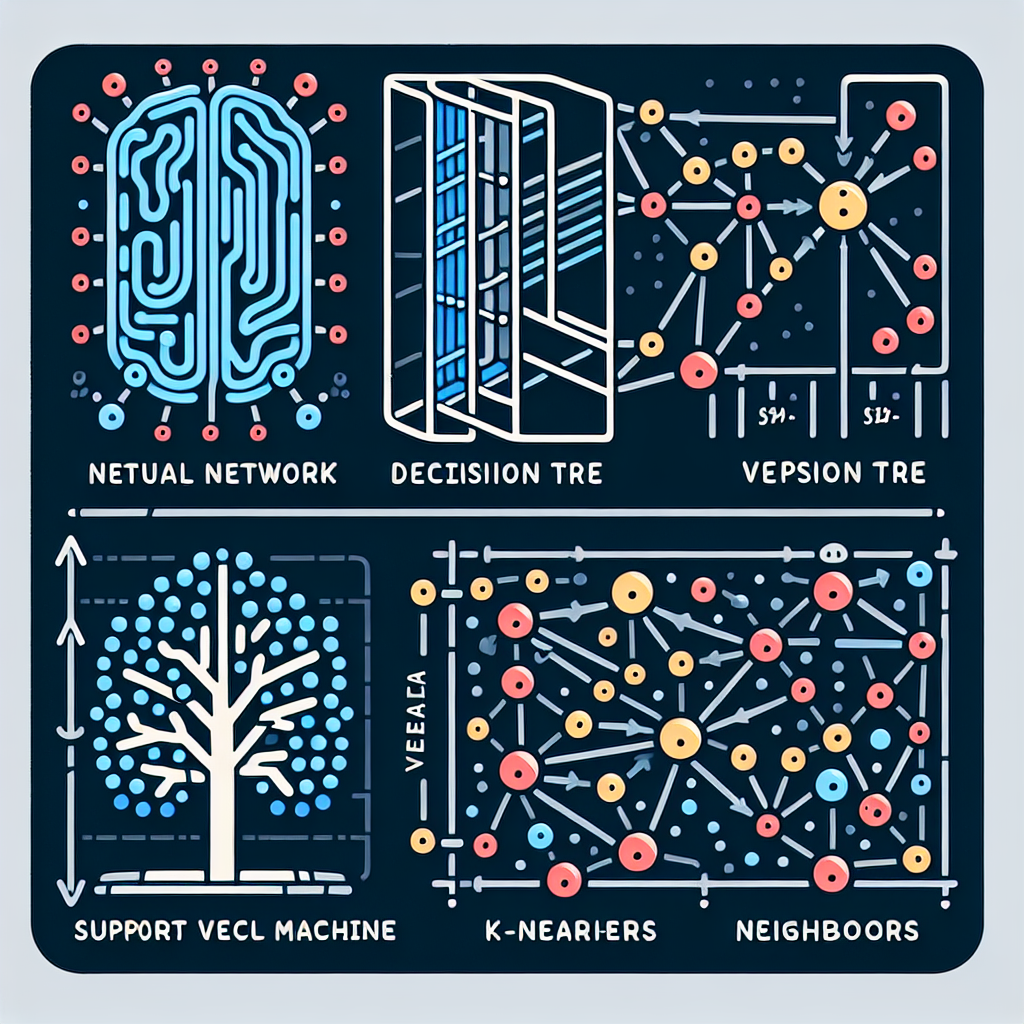
Neural networks, also known as artificial neural networks, are a type of machine learning model that is inspired by the structure and function of the human brain. They are a complex and powerful tool that has gained popularity in recent years due to their ability to handle large and complex datasets, and their success in various applications such as image and speech recognition, natural language processing, and predictive modeling.
At its core, a neural network is a network of interconnected nodes, or artificial neurons, that work together to process and analyze data. These nodes are organized into layers, with each layer performing a specific function in the overall process. The input layer receives the data, the hidden layers process it, and the output layer produces the desired result. This layered structure is what gives neural networks their name, as it resembles the structure of neurons in the human brain.
One of the key features of neural networks is their ability to learn and improve over time. This is achieved through a process called backpropagation, where the network adjusts its weights and biases based on the error between its predicted output and the actual output. This allows the network to continuously improve its performance and make more accurate predictions.
There are several types of neural networks, each with its own unique structure and function. The most commonly used type is the feedforward neural network, where the data flows in one direction from the input layer to the output layer. This type of network is often used for tasks such as classification and regression.
Another type is the recurrent neural network, which has connections between nodes that allow it to retain information from previous inputs. This makes it well-suited for tasks that involve sequential data, such as speech recognition and natural language processing.
Convolutional neural networks, on the other hand, are specifically designed for image recognition and processing. They use a technique called convolution, which involves applying filters to the input data to extract features and identify patterns. This makes them highly effective in tasks such as object detection and facial recognition.
One of the most complex and powerful types of neural networks is the deep neural network, also known as deep learning. This type of network has multiple hidden layers, allowing it to handle more complex and abstract data. Deep learning has been used to achieve groundbreaking results in various fields, such as computer vision, speech recognition, and natural language processing.
The applications of neural networks are vast and continue to expand as the technology advances. In the field of healthcare, neural networks have been used to analyze medical images and assist in disease diagnosis. In finance, they have been used for stock market prediction and fraud detection. In marketing, they have been used for customer segmentation and personalized recommendations. The possibilities are endless, and as more data becomes available, the potential for neural networks to revolutionize various industries only grows.
However, with great power comes great responsibility. Neural networks are not without their limitations and challenges. One of the main concerns is the lack of interpretability, as the inner workings of the network can be difficult to understand and explain. This can be problematic in fields where transparency and accountability are crucial, such as healthcare and finance.
In conclusion, neural networks are a complex and powerful type of machine learning model that has gained widespread use and success in various applications. Their ability to learn and improve over time, coupled with their versatility and scalability, make them a valuable tool in the age of big data. As technology continues to advance, it is likely that we will see even more advancements and breakthroughs in the field of neural networks, making them an essential component of our future.