
NVIDIA published this interesting research paper on ‘pruning’ large language models. It’s an interesting read because of the fact that language models are so power intensive to train. The general sy Read the whole paper here.
This paper, LLM Pruning and Distillation in Practice: The Minitron Approach, outlines a model compression strategy for large language models (LLMs), specifically targeting Llama 3.1 8B and Mistral NeMo 12B, and reducing them to 4B and 8B parameters. The approach leverages two pruning methods, depth and width pruning, combined with knowledge distillation to maintain model accuracy on benchmarks while reducing computational costs and model size.
Key points include:
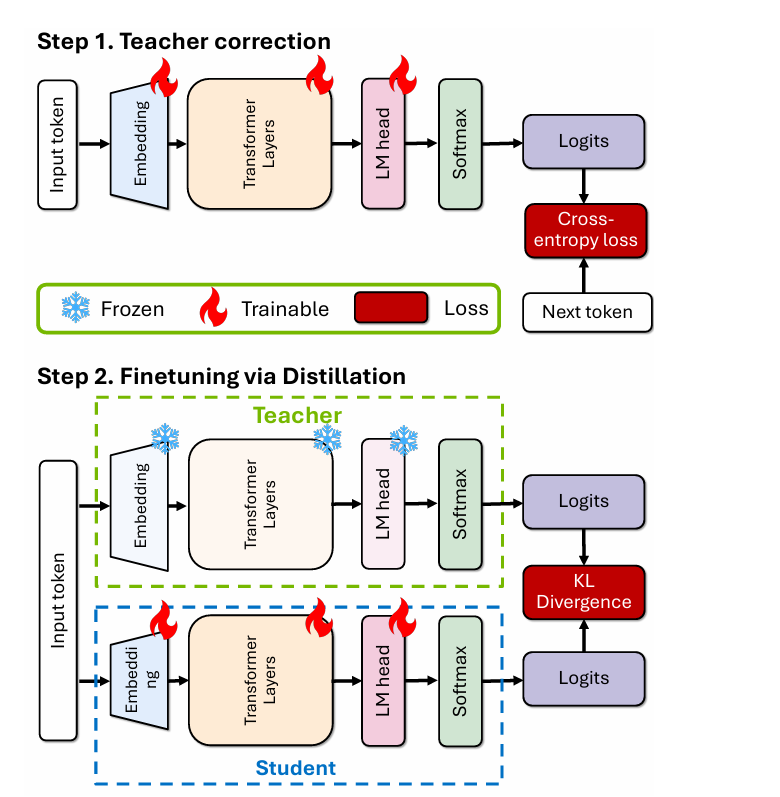
- Teacher Correction: The authors address data distribution differences by fine-tuning teacher models with a separate dataset before pruning and distillation.
- Pruning Techniques: Width pruning adjusts hidden and MLP dimensions without altering attention heads, while depth pruning reduces layers. They found width pruning to preserve accuracy better, while depth pruning improves inference speed.
- Distillation: Knowledge is transferred from the larger model (teacher) to the compressed model (student) using KL divergence loss, optimizing performance without the original training data.
- Performance: The pruned Llama and Mistral models (MN-Minitron-8B and Llama-3.1-Minitron-4B) achieve state-of-the-art results across language benchmarks, with Llama-3.1-Minitron-4B models exhibiting 1.8-2.7× faster inference speeds.
The authors release models on Hugging Face and demonstrate practical gains, providing a scalable, cost-effective compression framework for large model deployment.
In simpler terms, this research shows how to make large AI models smaller and more efficient without losing much of their performance. Here’s how it could impact AI development:
- More Accessible AI: By compressing large models, it becomes easier and cheaper for more people and organizations to use advanced AI, especially those who can’t afford the vast computing resources typically needed for huge models.
- Faster AI Applications: The pruned models run faster, meaning they can respond more quickly to user queries. This improvement could enhance real-time applications like chatbots, virtual assistants, or interactive educational tools.
- Energy and Cost Savings: Smaller models need less power to run, which lowers the environmental impact and makes AI systems more affordable to maintain over time.
- Broader Deployment: These more compact models can run on smaller devices (like phones or laptops) rather than only on large, expensive servers. This could bring advanced AI capabilities to more personal devices, improving accessibility and functionality for users globally.
Overall, these compression techniques help make powerful AI tools faster, cheaper, and more widely available, which could accelerate innovation in fields like healthcare, education, and personal tech.